
4o-image-generation
OpenAI introduced its latest image generation capability integrated into the GPT-4o model on March 25, 2025. OpenAI has long believed that image generation should be one of the primary capabilities of its language models, and GPT-4o represents their most advanced image generator to date, with the goal of producing images that are not only aesthetically pleasing but also practical.
Unlike previous models that focused on surreal or awe-inspiring scenes, GPT-4o's image generation is more practical, capable of generating "mainstream" images used in sharing and creating information. This includes a variety of images from logos to charts, which, when combined with symbols related to shared language and experiences, can convey precise meanings.
GPT-4o's image generation has been improved in several ways, enhancing its practicality and functionality:
- Text Rendering: GPT-4o can accurately render text and follow prompts precisely. It has the ability to integrate precise symbols with images, transforming image generation into a tool for visual communication. For example, it can generate street signs, menus, and invitations with clearly readable text.
- Multi-Round Generation: Since image generation is now a native capability of GPT-4o, images can be improved through natural conversation. GPT-4o can iterate based on images and text in the chat context, ensuring consistency throughout the process. For example, when designing video game characters, even after multiple modifications and experiments, the character's appearance can remain consistent.
- Instruction Following: GPT-4o's image generation can follow detailed prompts and pay attention to details. Unlike other systems that may struggle with 5-8 objects, GPT-4o can handle up to 10-20 different objects. The tighter integration of objects with their features and relationships makes control more precise.
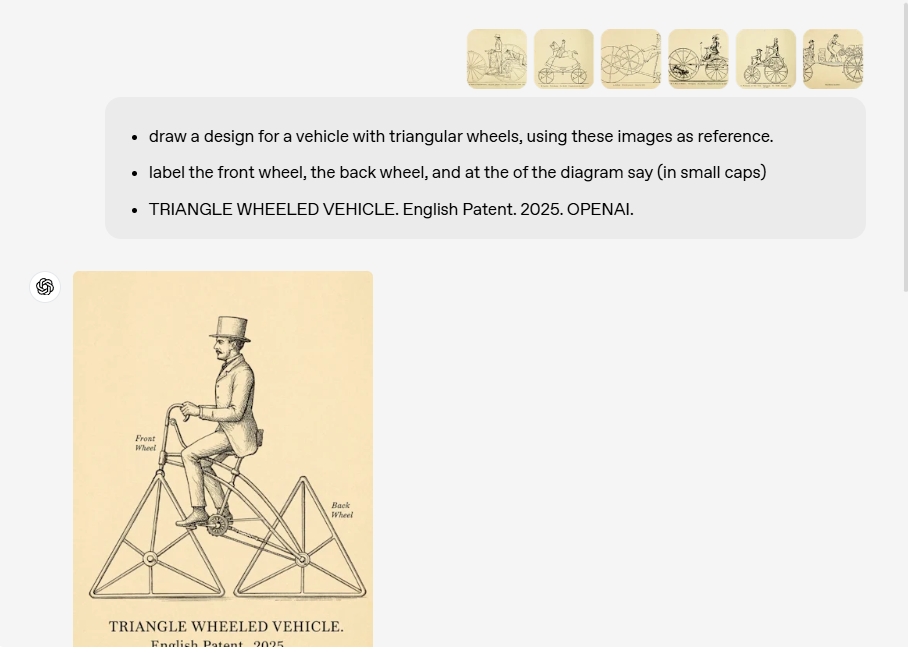
- Context Learning: GPT-4o can analyze and learn from user-uploaded images, seamlessly integrating their details into the context to provide information for image generation. This means you can upload an image as a reference and ask GPT-4o to generate a new image with a similar style or features.
- World Knowledge: The native image generation capability allows GPT-4o to connect its text and image knowledge, making it feel smarter and more efficient. This enables it to generate images based on code, create cocktail professional photo-level charts with recipe labels, generate visualization infographics on the cause of fog in San Francisco, and create educational posters for different types of whales, among other things.
GPT-4o has been trained on a large amount of data in various image styles, enabling it to convincingly create or transform images. This includes generating images in various styles, such as imitating paparrazi-style photos, Polaroid-style photos, old film photos, and highly realistic scenes and objects.
OpenAI acknowledges that its model is not perfect and currently has some limitations, which they plan to address through model improvements after release:
- Cropping: GPT-4o sometimes over-crops longer images, especially at the bottom.
- Hallucination: Like other text models, image generation may invent information, especially with prompts that have little context.
- High Binding Issue: When generating images dependent on its knowledge base, the model may struggle to accurately render more than 10-20 different concepts at once, such as a complete periodic table.
- Precise Drawing: The model may have difficulty generating precise charts.
- Multilingual Text Rendering: The model sometimes struggles to render non-Latin languages, with characters potentially being inaccurate or hallucinating, especially in more complex cases.
- Edit Precision: Requests to edit specific parts of image generation (e.g., typos) sometimes do not work as intended and may change other parts of the image or introduce more errors in a non-requested manner. The model has a known bug in maintaining consistency in user-uploaded face edits, but it is expected to be fixed within a week.
- Dense Information in Small Text: When required to render detailed information in very small sizes, the model is known to encounter difficulties.